

目录
3.1、访问小于0x00010000的内存地址(从0开始的64KB小内存地址)会触发崩溃
最近在使用CSDN app时,app时常推荐我去搜索“内存越界一定会导致程序崩溃吗?”的话题,由于最近几年一直在负责排查部门多个C++软件异常排查的工作,期间遇到过很多因为内存越界引发软件异常的问题实例,在这方面也积累了大量经验,所以决定今天在这里做一个关于C++内存越界的总结,系统全面地介绍内存越界相关的内容,给大家提供一个借鉴或参考。希望大家在了解这些内容以后,能更好地应对C++软件开发和维护过程中遇到的多种问题。
1、什么是内存越界?
内存越界是指代码操作某一变量时超出了该变量分配的内存范围,即操作了目标变量对应内存范围以外的内存区域。可能是读取越界的内存中的内容(即读越界),也可能是向越界的内存中写入了内容(即写越界)。下面我们来看几个内存越界的例子。
1.1、对数组的读越界
比如我们定义了一个:
int arr[10] = { 0 };如果我们通过数组下标访问了arr[-1]或者arr[11],那么arr[-1]是向前越界了,arr[11]是向后越界了。一般越界是越到变量分配的内存区域的后面区域,很少越界到当前访问的变量内存前面去的。有人可能会说,怎么可能会越界到负的下标(arr[-1])上去了呢?我们还真遇到过,后面我们给大家专门讲一个向前越界的实例。
很多时候从我们的思维定势出发,很多异常在我们的认知中好像是不大可能出现的,但软件在实际运行时各种意外都可能出现,打破我们认知的事会时不时发生。
1.2、执行strcpy时的写越界
再比如我们调用C函数strcpy将一个字符串拷贝到目标buffer:
char szDstBuf[10] = { 0 };
char* pInfo = "this is a test";
strcpy(szDstBuf, pInfo);显然这个”this is a test”字符串长度为14字节(加上\0结尾符则是15),已经超过了目标buffer szDstBuf的长度(10字节),所以执行strcpy后就发生内存越界了。你如果要将这段代码拷贝到visual studio中运行,这段代码执行后会报如下的错误:
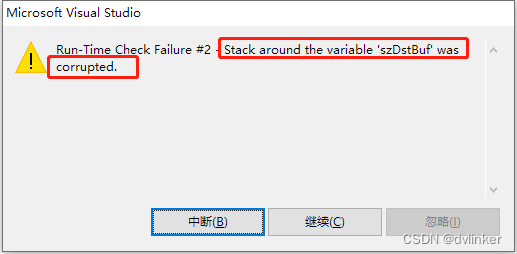
即szDstBuf局部变量周边的栈内存被破坏了,为啥这么说呢?因为执行strcpy时内存越界了,篡改了szDstBuf变量后面的内存了。
1.3、执行memcpy时的写越界
再比如我们对某个结构体对象进行memcpy操作时,拷贝的内存大小超过了目标结构体对象的内存大小导致越界了:
struct tagDeviceInfo
{
char szDeviceName[64];
int nDeviceType;
char szDeviceIp[32];
int nDevicePort;
}TDeviceInfo;
TDeviceInfo tDstDeviceInfo;
memcpy(&tDstDeviceInfo, pSrcDeviceInfo, nSrcInfoLen );此处的pSrcDeviceInfo是TDeviceInfo*指针类型,是从底层模块传上来的数据,nSrcInfoLen也是底层一起传上来的。那同样的结构体类型变量,怎么会出现长度不一致,致使memcpy时发生越界呢?这个我们后面会有专门的问题实例,暂时就不展开了。
2、内存越界一定会导致程序崩溃吗?
内存越界是否一定会引发程序崩溃呢?我之前做了个投票调查,大部分人都选择不一定会,还有部分朋友选择一定会导致崩溃。其实有些开发经验的人都知道,不是所有运行过程中发生的异常行为都会导致程序崩溃,内存越界也不例外,即内存越界不一定会引发程序崩溃。
3、有两种情况的内存操作是必然会导致程序崩溃的
下面讲的两种内存操作好像和内存越界话题没有直接的关系,之所以在此处详细讲述,一是因为要介绍的全面一些,二是引发这些内存访问问题可能是内存越界篡改了指针变量内存中的值(指针变量内存中存放的是要访问的目标内存地址)导致的。
3.1、访问小于0x00010000的内存地址(从0开始的64KB小内存地址)会触发崩溃
以Windows系统为例,从0开始的、小于0x00010000h的内存地址(64KB大小)区域被称为NULL地址内存区,这是系统故意设定的一块小地址内存区,是为了让程序员捕获对空指针(指向的内存区域)赋值。
任何试图来读取这个内存区域中的内容,或者向这个内存区域写入内容,都会触发内存访问违例,系统会强制将进程终止掉。关于64KB禁止访问的小地址内存区域,在《Windows核心编程》一书中内存管理的章节,有专门的讲述,相关截图如下所示:

在我们使用windbg分析dump文件时,如果发现崩溃的那条汇编指令中访问的内存地址是小于64KB的小地址内存区,则可以确定汇编指令崩溃原因是访问了不该访问的小地址内存区,触发了内存访问违例引发的崩溃。
引发这类内存访问违例一般有两个原因,一是访问了空指针,二是访问了内存被篡改的指针变量(将指针变量中正确的内存地址值篡改成很小的值,比如将正常的0x12357889篡改成0x00000001)。
3.2、用户态的代码访问了内核态的内存地址会触发崩溃
出于安全考虑,操作系统明确将用户态内存与内核态内存隔离开来,运行在用户态的代码不能访问内核态内存地址,运行在内核态的代码也是不能访问用户态内存地址的。
一般情况下,软件中的业务模块都是运行在用户态中的,进程中加载的系统内核模块是运行进程的内核态中的,比如驱动程序就是运行在内核态的。
那到底哪些地址范围是属于用户态的,哪些内存地址范围是属于内核态的呢?以Windows中的32位程序程序为例,系统会给32程序进程分配4GB的虚拟地址空间,一般情况下,32位程序进程的内核态和用户态各占一半,即用户态的内存地址范围为:0x00000000 – 0x7FFFFFFF,内核态的内存地址范围为:0x80000000 – 0xFFFFFFFF。

在Linux系统中,32位程序的4GB总的虚拟内存空间,用户态占3GB,内核态占1GB。
我们在使用windbg分析dump文件时,如果发现崩溃的那条汇编指令中访问的内存地址是内核态地址范围的,则可以明确汇编指令崩溃原因是用户态的代码访问了内核态的内存,这种行为是被系统禁止的。至于为啥会出现用户态的代码去访问内核态内存地址呢?肯定是存放内存地址的指针变量的内存中值被越界篡改导致的。
4、内存越界的分类
从越界操作类型来看,可以分为从内存中读取内容时的读越界和向内存中写入内容时的写越界,这个比较简单,也好理解。这里我们主要讲述一下从被越界的变量所处的内存区域的类型来看的分类。在看这种内存越界分类之前,我们先来看看C++程序内存的5大分区。
4.1、C++程序的内存分区

如上图所示,C++程序的内存(这里讲的都是虚拟内存)主要分全局内存区、堆内存区、栈内存区、常量内存区和代码内存区:
1)全局内存区:全局变量和静态变量都是在该内存区上分配内存的。
2)堆内存区: 通过malloc和new动态申请的内存都是在该内存区分配的。
3)栈内存区:函数中的局部变量是在栈上分配内存的,函数调用时参数的传递也是通过栈进行传递的。
4)常量内存区:该分区是用来存放常量值,如常量字符串等。该部分内存中的内容是固定的常量,是不允许修改的,程序结束后由操作系统统一回收。
5)代码内存区:加载到进程空间中的所有二进制文件占用的内存区,叫做代码段内存区。前面四种都是数据段地址,此处的代码内存区是代码段地址。
在exe主程序启动时,系统会先把exe主程序依赖的各个dll库先加载到进程空间中(进程的虚拟地址空间中),最后再将exe主程序加载到进程空间中,exe主程序及其依赖的dll库加载到进程空间中占用的内存都是从进程的虚拟内存中分配的。这些二进制文件占用的内存区就叫代码内存区。
关于程序内存分区,可以参见之前写的文章:
实例详解C++程序的五大内存分区![图片[5]-内存越界一定会导致程序崩溃吗?详解内存越界-卡核](https://ziquyun.com/main/csdn/img?url=https%3A%2F%2Fcsdnimg.cn%2Frelease%2Fblog_editor_html%2Frelease2.1.9%2Fckeditor%2Fplugins%2FCsdnLink%2Ficons%2Ficon-default.png%3Ft%3DM7J4&rfUrl=https%3A%2F%2Fblog.csdn.net%2Fchenlycly%2Farticle%2Fdetails%2F126442611) https://blog.csdn.net/chenlycly/article/details/120958761
https://blog.csdn.net/chenlycly/article/details/120958761
4.2、内存越界的分类
内存越界一般会发生在全局内存区、堆内存区和栈内存区,所以内存越界按照越界内存的类型来分,可分为全局内存越界、堆内存越界和栈内存越界。不同区域的内存越界,影响是不尽相同的:
1)堆内存越界肯可能会破坏堆块的头信息和尾部信息,导致堆内存管理出现异常;
2)栈内存越界一般可能会越界到函数中其他局部变量的内存上,即可能篡改了其他局部变量的值。
一般栈内存越界比较容易排查。全局变量和静态变量占用的是全局内存,是在进入main函数之前就分配好内存的,全局内存区的越界相对难查一些。
堆内存的越界可能会破坏堆块的头信息和尾部信息,可能会导致系统的对堆内存的管理出问题,在堆内存被越界破坏后,可能会导致后续的new或delete出现异常或者崩溃,引起程序“胡乱”崩溃,即每次崩溃时点都不太一样,崩溃时的函数调用堆栈有很大的不同。堆内存的排查相对要难很多。这三类内存越界,我们在实际的项目中都多次遇到过。
5、使用其他方法和专用的内存检测工具去排查内存越界问题
上述几个实例中的内存越界问题,都是比较简单的,排查起来也相对容易很多。但有些堆内存上越界,会导致软件出现胡乱的崩溃,基本无规律可循,根本没法下手排查的。这个时候就需要使用内存检测工具和其他排查手段来排查了。
常用的辅助排查方法有添加打印、分段注释代码、历史版本对比法等:
1)添加打印:
可以在出问题的上下文中添加打印,将相关变量的值打印出来,尽可能地添加多行打印,看看到底时从哪一行代码开始变量的值就变了。然后找到引发异常的线索。通过打印日志不仅可以排查业务上的问题,也可以辅助排查软件运行过程中遇到的异常崩溃等,是排查软件问题最直接的手段之一。一个大型的软件系统,打印日志必须是完备的,必不可少的。
2)分块注释代码:
可以分块注释代码,也可以分行注释代码,看看问题到底是哪块或哪行代码引起的。分块注释代码,在部分场合下是个很好的逐步排查问题的手段。
3)历史版本比对法:
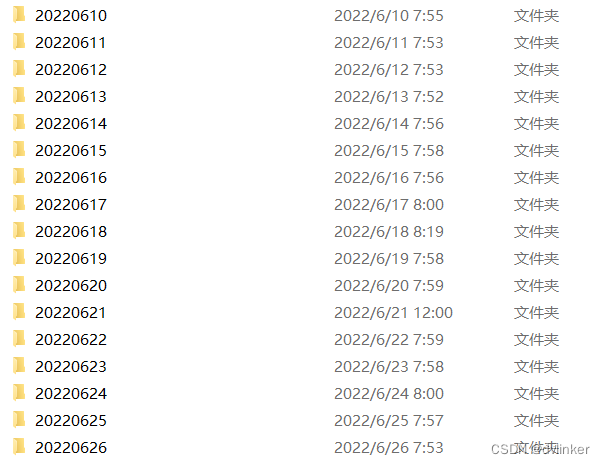
在时间上采用二分法方式,安装多个历史版本,看看问题是从哪天开始出现的,然后仔细检查一下出问题前一天提交的代码,大概率就能找打问题了。不过这种方法依赖于每天都要编译版本,我们这边新需求处于开发阶段时基本每天都会自动编译版本(自动化编译脚本驱动的自动化版本编译系统),然后将版本保存到服务器上,如下:
这样才有查看历史版本的详细颗粒度,这样才更有效。
这个方法比较适用于客户端软件,因为客户端可以随意安装不同时间的版本,如果是服务器程序,很多时候是多个业务捆绑在一起一起部署到服务器上的,可能会替换单个软件业务单元要麻烦很多。历史版本比对发很有效果,我们已多次使用该方法定位了多个问题。
关于排查软件异常常用方法的更详细阐述,可以参见:
排查C++软件异常的常见思路与方法(实战经验总结)https://blog.csdn.net/chenlycly/article/details/120629327 此外,常用的内存检测工具则有Valgrind和AddressSanitizer等。关于Windows和Linux下排查C++软件异常的常用调试器与内存检测工具,可以参见我之前写的文章:
Windows和Linux下排查C++软件异常的常用调试器与内存检测工具详细介绍https://blog.csdn.net/chenlycly/article/details/126381865




暂无评论内容