
文章目录
4、Direct Computer基础知识
使用WIC完成了GIF帧的加载、解码、转换等操作之后,剩下的核心任务就是使用Direct Computer计算管线来进一步完成GIF帧预处理任务了。这里有必要先了解一下Direct Computer的一些相关基础知识。
4.1、Direct Computer简介
DirectCompute是一组通过COM形式封装的API,可以使Windows平台上的程序利用GPU进行并行化的通用计算。DirectCompute是DirectX的一部分。虽然DirectCompute最初在DirectX 11 API中得以实现,但支持DX10的GPU可以利用此API的一个子集进行通用计算,支持DX11的GPU则可以使用完整的DirectCompute功能。DirectX12中继续保留并支持DirectComputer接口,并做了相应的功能扩展与性能提升。
Direct Computer利用GPU上的并行计算能力,并且结合HLSL语言,实现了称为Computer Shader的通用计算为目的的着色器。因此通过Direct Computer COM接口,以及Computer Shader就可以利用GPU独立的完成一些通用计算为目的的应用场合。这样就把过去依托于传统渲染管线的所谓GPGPU方式的一些计算任务,移植到专门的以通用计算为目的的轻量级的Direct Computer通用计算管线上。这样就可以独立的使用Direct Computer。并且也可以和DirectX中的其它部分无缝融合。
4.2、Direct Computer编程基本框架
在D3D12中Direct Computer的基本编程过程如下:
1、创建D3D12设备(与D3D无缝集成的基础);
2、编写并编译Computer Shader,创建Direct Computer管线的PSO及根签名;
3、创建数据缓冲(输入及输出缓冲);
4、创建数据缓冲视图/描述符及描述符堆(主要用于操作数据);
5、录制计算管线的命令列表,重点记录Dispatch命令函数,并调用ExecuteCommandLists运行Computer Shader对数据进行计算;
6、获取计算结果;
7、释放资源;
其中创建3D设备、准备数据缓冲、创建描述符及描述堆、还有创建PSO对象等操作与D3D12图形渲染管线中的对应过程大同小异,就不多啰嗦了。之后的重点将放在Computer Shader和Disptch上面,因为这是理解整个DirectComputer的核心知识。
4.3、Computer Shader简介
Computer Shader是使用HLSL语言编写的用于计算数据(通用计算)的着色器程序。HLSL语言采用类似C/C++语法设计,但不支持指针,细节上则跟C/C++差别较大。Computer Shader传承HLSL语法的精髓,并且为通用计算做了很多必要的改进,所以在一些细节语法上与其它Shader有一定区别。HLSL语言是严格区分大小写的,注释同C/C++注释。
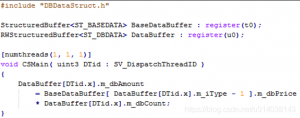
4.4、Computer Shader示例

上面的例子代码中#include命令含义与C/C++中的#include命令含义相同,就是包含一个头文件,是HLSL中的预处理命令之一。
StructuredBuffer可以理解为是一个Computer Shader内置的模版类,<ST_BASEDATA>就是这个模版类的实例化参数,整句意思就是实例化一个由ST_BASEDATA结构体类型为元素的结构化动态数组(缓冲/Buffer)。BaseDataBuffer就是上面模版类经实例化后自定义的对象名。
register(t0)就是HLSL中的语义文法,用以说明冒号:前的对象(主要是数据/缓冲等)所在寄存器类型为t(t = Texture)并且序号为0。关于语义文法的目的,在本教程第十二篇中已经做了详细描述,它其实就是为了标明寄存器的使用策略,从而使的Shader编译器可以将整个函数的调用过程全部从编译结果中完整”拆除“,从而使HLSL中所有的函数最终都成为”内联“展开形式的。
用寄存器直接标明变量之后,无论函数定义在哪里(某个Shader文件中),或者在哪里(另一个Shader文件中)被调用,编译器(或者说链接器更确切)都可以轻松的知道某个数据其实就是一直在某个寄存器中,或者说某个寄存器就一直是某个数据,从而不用去互相之间引用源代码。
类似的,RWStructuredBuffer就是一个可读写的结构化缓冲的模版类,其余要素与前述普通结构化缓冲(StructuredBuffer)相同。主要区别是,普通缓冲(StructuredBuffer)只能读取,而RWStructuredBuffer可以读写,所以它通常被用来当作输出缓冲。
[numthreads(1, 1, 1)]是HLSL中函数的扩展语义文法说明,用以说明组织计算的GPU线程块(Thread Box)的最小单元(后面详述)。这也是Computer Shader中最重要最核心的一个函数语义文法(也被称为函数属性文法,懂编译原理的话就知道语义可以在抽象语法树中用扩展属性文法来描述,因此往往对二者不做详细区分,即说语义也可以,说属性也可以),是区别于别的Shader的重要标志。
void CSMain( uint3 DTid : SV_DispatchThreadID ){…}是Computer Shader的主函数。作用与C/C++中的main函数类似,是计算着色器过程开始的地方。
DataBuffer[DTid.x].m_dbAmount
= BaseDataBuffer[DataBuffer[DTid.x].m_iType-1].m_dbPrice * DataBuffer[DTid.x].m_dbCount;
是Computer Shader程序中的语句。例子中是简单的数组下标表达式语句。语义与C/C++中等价的数组下标表达式类似;
在例子中所有冒号:之后的语法部分以及类似CSMain函数开头的以方括号[]包围的部分就是之前已经提到过的语义文法说明了。它的核心目的就是为了方便Shader编译器把所有的HLSL程序中的函数都彻底变成“内联展开”形式,以适应GPU运行的特殊架构要求。
本质上这样的语法一般是一门语言中比较低级的语法部分,这里的低级的说法类似于说汇编语言相较于高级语言如C++、Java等是低级语言时的含义,表示更贴近硬件,或者说保留了一些硬件要求的特征在里面的意思。类似的语法设计还有C/C++中的指针相关语法等,这也是语言中比较低级的部分,或者说更贴近硬件特性的部分,因为指针表示的就是内存中的地址。这些语法特性的加入,使得我们要想彻底掌握这些语法,就必须要了解相当多的硬件知识。这也是为什么在本系列教程中,一直反复的讲解很多必要的GPU相关硬件知识的原因。否则,对于这些特殊的语法要素,学习掌握就会不彻底,只知其然,不知其所以然。
进一步的,扩展来说,我把多线程的一些相关知识,包括GPU线程的知识也归结为此类。总之,就是说要彻底的掌握关于Shader编程的所有方面,就必须要对CPU、GPU等等的硬件知识有相当的了解。因此在本系列教程中,会不断的穿插讲解很多必要的相关的硬件知识,当然要想进一步了解,就建议大家再扩展阅读很多这方面其它的相关资料。
4.5、[numthreads(x, y, z)]语义文法详解
[numthreads(x,y,z)]属性语句是理解Computer Shader并行计算的核心。该语句定义了可执行的线程块(也称线程盒,Thread Box)线程数量,其中每个线程可以被称为一个Thread Item(线程项)。当一个Computer Shader被分派执行的时候。线程盒可以理解为一个由x,y,z坐标为参数的线程项组成的线程盒(立方体,threads box/threads cube)。一个线程盒中的线程总数就是
x
∗
y
∗
z
x*y*z
x∗y∗z。
在理解上,首先numthreads中的x、y、z参数指定了其修饰的Computer Shader主函数(入口函数/入口点)所代表的线程项组成的线程盒中,或者说是线程三维数组中,每个维度下标的上限。
其次要理解的是,这里虽然可以将线程盒理解为线程三维数组,但是不能指定某个上限最小值为0,即不能指定类似numthreads[0,y,z]或numthreadsp[x,0,z]等形式的语义说明,也就是说任何一维最小上限只能指定为1,表示该维度最少有”一片“线程被执行。这与指定一般的数组时一样,即不能定义0维度大小的数组。因此当只需要一个线程项执行的时候就需要指定语义为numthreads[1,1,1],这也是一种较常用的形式(后面还会详细解释)。
又次,当指定某个维度的上限为1时,就相当于忽略这个维度。比如当只需要2维线程盒来参与计算时,可以指定属性为numthreads[x,y,1]这种形式,其中x,y可以根据算法需要指定一个大于0的整数。
再次要理解的就是在线程盒中,也就是在线程三维数组中,任何一个元素(Thread Item)都是一个执行被语义修饰的Computer Shader主函数的GPU子线程。
最后需要理解的就是,Computer Shader主函数及子函数中一般以这个语义指定的维度大小来索引一组数据(常常是数组)。方法就是将某个uint3(HLSL中的向量数据类型)类型入口参数用SV_GroupThreadID语义修饰后用作数组元素的下标索引。比如:
[numthreads(4, 4, 2)]
void CSMain( uint3 n3ThreadBoxIndex : SV_GroupThreadID)
{
...
anydata[n3ThreadBoxIndex.xyz] = ...;
...
}
代码中anydata[n3ThreadBoxIndex.xyz]的含义类似于c++代码中:
anydata[n3ThreadBoxIndex.x][n3ThreadBoxIndex.y][n3ThreadBoxIndex.z]
这样数组下标的上限就分别对应是4-1=3、4-1=3、2-1=1,索引范围分别是[0-3]、[0-3]、[0-1]。而在代码中之所以用xyz来代用的意思就是说GPU在具体执行时会总共调用:
4
∗
4
∗
2
=
32
4*4*2=32
4∗4∗2=32
个线程,而每个CSMain函数入口参数n3ThreadBoxIndex的xyz分量都被指定了一个对应的“坐标”。下图更形象的解释了这个含义:

从图中就可以明白的看出一个线程盒或者说线程三维数组的结构原理了,也就明白了SV_GroupThreadID参数的含义,它就是一个线程盒内部的具体每个线程项的坐标,可以直接被用来索引一个三维的数组,或者索引小于三维的二维或一维数组。
这样当一个并行算法,比如固定维度的4D颜色值的简单混色乘法,需要一个维度的下标量索引的时候,就可以使用这个方式来索引,此时可以定义numthreads的第一个分量上限为1,代码上基本就可以套用公式如下来写了:
StructuredBuffer<float4> colorA;
StructuredBuffer<float4> colorB;
RWStructuredBuffer<float4> colorC;
[numthreads(4, 1, 1)]
void CS_Color_mul( uint3 n3ThreadBoxIndex : SV_GroupThreadID)
{
...
colorC[n3ThreadBoxIndex.x] = colorA[n3ThreadBoxIndex.x]*colorB[n3ThreadBoxIndex.x];
...
}
上面示例代码中,colorC、colorA、colorB是4D颜色向量的数组,因为线程盒函数属性中只有第一维不为0,所以就可以忽略y、z两个维度的索引,只保留使用x索引即可,这是n3ThreadBoxIndex.x的值范围就是0-3,正好用来索引每个color数组元素的4个分量。
最终在运行时为每个color数组元素启动一个具有
4
∗
1
∗
1
=
4
4*1*1=4
4∗1∗1=4个线程的线程盒,而这个线程盒中的所有线程项都是并行执行的。综合起来,线程项运行以及索引数据的示意图如下所示:

从图中可以看出第i个线程盒中的每个线程项都并行运行,并且每一个都索引到了一个颜色分量数据。当然实际中,4D的颜色分量完全可以在一个线程项中用rgba下标来一次性操作,因为最终GPU上的ALU是按照操作最小4个分量的向量来设计的,所以在一个线程项中完全可以一次性操作一个4D向量的所有分量,甚至可以操作4*4大小的矩阵,这本来就是3D图形计算中的基本要求。这里之所以示例这样,完全是为了演示一个线程盒中不同的线程项可以操作具体一个数据项的不同分量而设计的,并且可以根据数据项(或复杂结构体数组元素)的维度大小来定义具体线程盒的大小,这样就可以一个线程盒作为操作一个多维数据项的最小单元,其内部维度根据数据项的维度来确定,这样在一些有精细结构的数据项中,就可以利用GPU的线程盒来并行操作每一个最小的数据元。这也是一般的使用Computer Shader操作数据时的思路。
4.6、通过Dispatch来批量发起GPU线程盒
有了上面这个最简单的操作颜色分量的线程盒的Computer Shader的示意性例子,那么接着需要做的就是在程序的C++代码中调用DirectComputer接口函数Dispatch来启动它们。这有点像在程序中最终通过调用Draw Call来启动渲染过程一样。Dispatch函数现在是图形命令列表(ID3D12GraphicsCommandList)接口的一个函数,原型如下:
void ID3D12GraphicsCommandList::Dispatch(
UINT ThreadGroupCountX,
UINT ThreadGroupCountY,
UINT ThreadGroupCountZ
);
通过这个函数的声明,应该立即发现一个新的名词Thread Group,这又是什么意思呢?貌似它也有X、Y、Z三个坐标,同时作为函数的参数。其实这就是说Dispatch按照X、Y、Z三个坐标,告诉GPU将线程盒再组织成一个三维线程组的形式。形象的可以将每个线程盒想象成一个集装箱,而Dispatch的意思就是以怎样的三维形式摆放这些集装箱。最终Dispatch和线程盒中的numthreads语义说明共同构成了两个层面的三维线程项结构。举个形象的例子来理解就是线程盒是一套房子,线程项是这套房子中的一个房间,而Dispatch则将这些房子组合成了一栋楼!
接着以前面的那个操作颜色分量的线程盒的例子,那么假设需要操作1024个4D颜色组成的数组,这时Dispatch可以如下调用:
pICommandList->Dispatch(1024,1,1);
当这些线程盒运行后的情景就可以如下图所示:

图中最下面一行表示color数组,原本应该有三个分别表示colorA、colorB、colorC三个数组,这里为了更简化,方便大家理解,所以只画了一个来表示。这些颜色数组都有1024个元素,每个元素都有4个分量。对应到每个线程盒就操作数组中的一个对应元素。同样例子中仅展示了Dispatch第一维为1024个线程盒的情况,这样线程盒就排成了一维的结构,这样安排是为了方便大家形象的先理解低维的情况,毕竟理解3维数组有时候都比较麻烦,更何况这里的3维线程盒还嵌套两层3D结构。所以这里大家先理解两个一维结构所表示的意思,也为理解更高维的情况打下基础。
在此基础上,大家可以把每个4D颜色分量想象成是2D图片上的一个像素,也就是4D颜色数据组成了2D数组,接着还是我们的操作4个不同颜色分量的线程盒来完成颜色混合操作,那么Dispatch应该怎样调用呢?这个问题就留给大家先思考了,后面我们在介绍如何操作GIF帧的时候就会明白具体要怎么弄了。当然如果你已经明白了,那就给自己点个赞先!
4.7、SV_GroupID、SV_DispatchThreadID、SV_GroupIndex语义
在理解了线程盒以及用Dispath发起线程盒的运行之后,接着让我们再来看下其它的几个重要的语义,以及用它们所修饰的参数的具体含义。
理解了之前的例子之后,让我们来思考一个问题,假如将线程盒想象成了集装箱,并且用Dispatch将它们按照3维方式摆放在了一起,那么在每个线程盒内部怎么知道它所在的集装箱整体上在什么位置呢?其实这等同于在Thread Box内接受Dispatch设定的维度上限范围内的具体线程盒的三维索引。这时SV_GroupID语义就派上用场了,也就是在Computer Shader主函数的参数列表中,再加入一个uint3类型的参数,并用SV_GroupID语义修饰说明,具体如下所示:
[numthreads(4, 1, 1)]
void CS_Color_mul( uint3 n3GroupID : SV_GroupID,uint3 n3ThreadBoxIndex : SV_GroupThreadID)
{
...
}
如上代码中声明了这个参数之后,那么在Computer Shader主函数中就可以引用其x,y,z分量来明确知道当前线程盒所在的具体索引位置。与SV_GroupThreadID语义参数类似,通常可以使用这个参数来索引全局的大的数据项,比如索引全局的结构化缓冲中的大的数据项,或者索引一个3D Texture中的具体某个像素。而SV_GroupID语义参数的上限就是调用Dispatch函数中指定的值。即SV_GroupID语义参数的索引范围是从0到Dispatch函数对应参数的X-1,Y-1,Z-1。因此当Dispatch某个参数为1时,即当前这个维度只有一个索引,那么就可以在Computer Shader的线程盒函数中忽略它,或者可以不用明确指定它。
另外在Computer Shader线程盒函数中还可以使用SV_DispatchThreadID语义参数和SV_GroupIndex语义参数。
SV_DispatchThreadID语义参数就相当于将线程盒内的一个线程项(Thread Item)的局部坐标(SV_GroupThreadID语义参数),偏移到由Dispatch发起的整体的全部线程盒所组成的线程组的全局坐标系中,具体计算公式如下所示:
uint3 n3GlobalThreadItem:SV_DispatchThreadID;
uint3 n3ThreadItem:SV_GroupThreadID;
uint3 n3Group;
[numthreads(X,Y,Z)];
n
3
G
l
o
b
a
l
T
h
r
e
a
d
I
t
e
m
.
x
y
z
≡
n
3
G
r
o
u
p
.
x
y
z
∗
u
i
n
t
3
(
X
,
Y
,
Z
)
+
n
3
T
h
r
e
a
d
I
t
e
m
.
x
y
z
;
n3GlobalThreadItem.xyz \\equiv n3Group.xyz * uint3(X,Y,Z) + n3ThreadItem.xyz;
n3GlobalThreadItem.xyz≡n3Group.xyz∗uint3(X,Y,Z)+n3ThreadItem.xyz;
注意公式中
u
i
n
t
3
(
X
,
Y
,
Z
)
uint3(X,Y,Z)
uint3(X,Y,Z)表示numthreads语义说明中的三个上限,即线程盒(Thread Box)的大小,其中的乘法是指简单的分量相乘,不是向量内积也不是外积,而是类似颜色的分量相乘。整个公式的含义就是将整个线程组按照线程盒大小放大,然后在加上具体的线程项的坐标,就得到了线程项在整个大的线程组中的索引位置。
而SV_GourpIndex语义参数类型是uint,就是将线程项复杂的全局3维坐标计算为等价的1维坐标偏移,这与在C++代码中计算高维数组的一维等价坐标的方法是一样的,具体的公式如下所示:
n
G
r
o
u
p
I
n
d
e
x
=
n
3
T
h
r
e
a
d
I
t
e
m
.
z
∗
(
n
u
m
t
h
r
e
a
d
s
.
x
∗
n
u
m
t
h
r
e
a
d
.
y
)
+
n
3
T
h
r
e
a
d
I
t
e
m
.
y
∗
n
u
m
t
h
r
e
a
d
s
.
x
+
n
3
T
h
r
e
a
d
I
t
e
m
.
z
nGroupIndex = n3ThreadItem.z*(numthreads.x*numthread.y) + n3ThreadItem.y*numthreads.x + n3ThreadItem.z
nGroupIndex=n3ThreadItem.z∗(numthreads.x∗numthread.y)+n3ThreadItem.y∗numthreads.x+n3ThreadItem.z
上述最后两个语义参数一般并不常用。因为在Computer Shader中通常都是使用结构化数组来描述数据,所以使用SV_GroupID来索引数组元素,而使用SV_GroupThreadID来索引一个数组元素中的子数据项即可。这也是使用Computer Shader进行数据的并行通用计算时的一般思路。
在MSDN中用了一副图来说明这四个语义参数的含义,在这里引用一下:

这里要注意的是MSDN中是将本文中说的Thread Box称之为Thread Group,而Dispatch形成的线程组称之为Thread Groups,同时将线程项(Thread Item)称之为Thread。为了区分CPU线程和GPU线程(或者称之为Computer Shader线程),同时因为中文词法中没有类似英文中的单数复数的说法,所以本文特意都转义成了线程组(或者线程盒组更确切)、线程盒、线程项这样的说法,方便大家理解和记忆。当然这是非官方非正式的说法,纯属一种习惯。当然我是参考了一下OpenCL中的一些叫法。终极目的就是为了方便大家的理解。毕竟理解了才能应用。而我认为MSDN中的叫法,以及这四个语义的命名都是毕竟令人迷惑的说法,所以就大胆的转义一下,或者用现在流行的说法就是“说人话”。










![[转]我国CAD软件产业亟待研究现状采取对策-卡核](https://www.caxkernel.com/wp-content/uploads/2024/07/frc-f080b20a9340c1a89c731029cb163f6a-212x300.png)




