

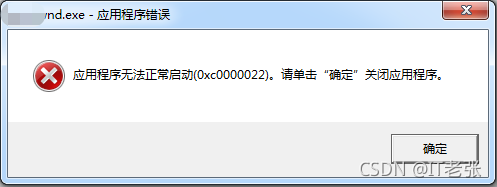
最近几年工作中很大一部分内容是排查软件运行过程中遇到的各种异常,无论是底层的网络模块、协议模块和组件模块,还是上层的UI模块,都处理过多次,见识了各式各样的C++异常或崩溃,积累了大量的实战经验,在此给大家做个分享。本文将详细讲述Windows系统中C++软件异常的分类以及常用的排查方法,给大家提供一个借鉴与参考。
![图片[1]-C++软件异常分析概述-卡核](https://ziquyun.com/main/csdn/img?url=https%3A%2F%2Fimg-blog.csdnimg.cn%2Fc36233a0f57446fdbde2187ce058ab7b.png%3Fx-oss-process%3Dimage%2Fwatermark%2Ctype_d3F5LXplbmhlaQ%2Cshadow_50%2Ctext_Q1NETiBAZHZsaW5rZXI%3D%2Csize_15%2Ccolor_FFFFFF%2Ct_70%2Cg_se%2Cx_16&rfUrl=https%3A%2F%2Fblog.csdn.net%2Fchenlycly%2Farticle%2Fdetails%2F123991269)
1、软件异常的分类
常见的软件异常有变量未初始化、内存越界、内存访问违例、stack overflow线程栈溢出、空指针与野指针、死循环、死锁、内存泄露、GDI对象泄露、函数调用约定不一致导致的栈不平衡等。
有的异常会立即导致软件崩溃。有的异常在运行一段时间或者长时间运行后才会导致崩溃,比如内存泄露和GDI对象泄露。有的异常并不会导致崩溃,只会导致软件发生堵塞或卡死,比如死循环和死锁。
还有一类问题会导致业务代码执行上的异常,这类问题不会导致软件崩溃,会导致业务代码没有按照正常逻辑或者分支被执行,导致业务逻辑出异常。比如函数抛出异常导致部分代码被跳过,即该执行的代码没有执行到,导致后续业务代码执行时出现逻辑异常。正常情况下,这些被跳过的代码会执行一些判断,会设置一些变量的值,会直接影响后续代码的判断与执行逻辑,所以会导致后续代码在运行时出现业务逻辑上的异常。这样的问题我们以前遇到过几次。
再比如系统API函数的lasterror被覆盖,导致后续判断lasterror值的条件判断出现逻辑上的错误,即产生了误判。这个问题我们以前也遇到过,在libjingle库的开源代码中添加了一个打印,因为开源代码的接口封装的层次比较深,导致我们在添加日志打印的代码时没看出会把lasterror值覆盖的问题。具体的是,添加的那句打印日志的代码中调用系统API函数,该行打印日志的代码执行完后就会把其前一句的开源库代码产生的lasterror值给覆盖了。而在打印日志下面的下一句开源代码中的接口内部会判断上一句开源代码执行后的lasterror值,因为该lasterror值被覆盖了,所以导致对lasterror的判断条件出现误判,导致后续的业务代码出现了逻辑上的异常。
对于GDI对象泄露,是使用GDI对象去绘制窗口导致的,绘制操作执行完后没有去释放GDI对象。GDI对象包括Pen画笔、Brush画刷、BItmap位图、Font字体、DC设备上下文、Region区域等。程序中如果有GDI对象泄露,不会立即导致异常或崩溃,当程序进程的GDI对象总量达到10000个左右时就会出现异常,出现闪退崩溃。在Windows系统中,单个进程的GDI对象上限是10000个,当进程的GDI对象快要接近10000个时,就会出现GDI函数绘制异常,接着就会产生崩溃。其实对于GDI对象泄露的排查,相对于内存泄露,要简单的多,只需要使用GDIView软件工具找出发生泄露的是哪种GDI对象,结合代码就能很快查出来。GDIView工具的界面如下所示:
![图片[2]-C++软件异常分析概述-卡核](https://ziquyun.com/main/csdn/img?url=https%3A%2F%2Fimg-blog.csdnimg.cn%2Ff532cc1f519c43469c4a8db2ac20713c.png%3Fx-oss-process%3Dimage%2Fwatermark%2Ctype_d3F5LXplbmhlaQ%2Cshadow_50%2Ctext_Q1NETiBAZHZsaW5rZXI%3D%2Csize_20%2Ccolor_FFFFFF%2Ct_70%2Cg_se%2Cx_16&rfUrl=https%3A%2F%2Fblog.csdn.net%2Fchenlycly%2Farticle%2Fdetails%2F123991269)
2、使用windbg分析软件异常
windbg是Windows平台一个最强大、最通用的软件调试分析工具,Windows平台主要使用它来分析各种软件异常。
大部分异常崩溃问题,软件中的异常捕获模块(大家都在使用开源的carshreport异常捕获库)都能捕获到,并将发生异常时的上下文保存到dump文件中,事后可以使用windbg静态分析这些dump文件。
对于有些不会导致软件崩溃的异常,比如死锁、死循环和内存泄露,需要我们将windbg挂载到目标进程上进行动态分析了。
对于少数异常捕获模块捕获不到的异常,比如程序在运行过程中发生闪退,需要将windbg附加到目标进程上跑,即windbg和其附加的目标进程绑定在一起运行,一旦目标进程出现异常,windbg就能立即感知到并中断下来。将windbg附加到目标进程上后,我们需要想办法去复现异常,异常产生后windbg会捕获到并中断下来,此时可以直接去使用windbg命令去分析了,也可以将使用.dump命令将异常上下文导出到dump文件中供事后分析。可能分析问题会比较耗时,可能出问题的电脑是同事的或者是领导的,不能一直占着别人的电脑,此时可以选择导出dump文件供事后用windbg分析。
对于一些弹框报错或者软件发生卡死的异常,软件一直卡在这个点上(目标进程还在),此时可以直接将windbg挂上去,这个时间点已经出现了异常,但挂载windbg的时机也不晚,也是可以获取到异常的上下文信息的。对于这类问题,不要点击报错的确定按钮,或者不要急于通过资源管理器去强杀目标进程,将目标进程保留住,此时将windbg挂上去正是时候,也能获取到完整的异常上下文信息。这些异常可能是事后很难复现的,必须要逮住这个机会,将windbg直接挂载到出问题的进程上进行分析。错过这个机会,下次可能就很难复现了,这样软件中就留下了很大的隐患。
3、除windbg之外的常用异常排查方法
当然除了windbg的静态分析和动态调试,还有一些其他的常用方法,这些方法也很重要,也需要掌握,比如使用VS直接调试(Debug或Release调试)、附加到进程中调试、添加打印日志、历史版本比对法(找出开始出问题的那个时间点)、分块注释代码、设置数据断点(对内存进行实时监控)等。有时,我们需要将多种方法结合起来使用。
对于业务上的一些逻辑异常,一般需要通过添加日志打印来排查。还有一种典型的异常是软件运行过程中遇到了错误,软件自己判断出来了,并认为是致命性错误,会直接调用abort或者exit强行终止进程的。比如在开源的jsoncpp库中,在解析到异常的json节点时出错,会直接调用abort强行终止整个进程。再比如在开源的webrtc库中,在用new申请堆内存失败时,webrtc库内部会认为发生了致命性的错误,也会调用abort强行终止进程。这类主动强行终止进程的,异常捕获模块是捕获不到的异常,因此是不会生成dump文件的。
这类情况可以将windbg挂载到目标进程上跑,一旦调用abort接口,windbg就会中断下来,此时查看函数的调用堆栈就能看到是何处代码触发的问题了。为啥windbg能感知到,软件中安装的异常捕获模块捕获不到呢?因为软件本身并没有RaiseException,是软件主动终止进程的。那为啥windbg能感知到呢?因为abort接口中会产生一个SIGABRT终止信号通知,这个调试器能感知到,于是windbg就产生了中断。此时使用kn命令查看函数调用堆栈,就可以看到是哪些接口触发的问题了。可以直接在Visual Studio中go到abort函数实现处,查看abort函数的内部实现了,如下:
/***
*void abort() - abort the current program by raising SIGABRT
*
*Purpose:
* print out an abort message and raise the SIGABRT signal. If the user
* hasn't defined an abort handler routine, terminate the program
* with exit status of 3 without cleaning up.
*
* Multi-thread version does not raise SIGABRT -- this isn't supported
* under multi-thread.
*
*Entry:
* None.
*
*Exit:
* Does not return.
*
*Uses:
*
*Exceptions:
*
*******************************************************************************/
void __cdecl abort (
void
)
{
_PHNDLR sigabrt_act = SIG_DFL;
#ifdef _DEBUG
if (__abort_behavior & _WRITE_ABORT_MSG)
{
/* write the abort message */
_NMSG_WRITE(_RT_ABORT);
}
#endif /* _DEBUG */
/* Check if the user installed a handler for SIGABRT.
* We need to read the user handler atomically in the case
* another thread is aborting while we change the signal
* handler.
*/
sigabrt_act = __get_sigabrt();
if (sigabrt_act != SIG_DFL)
{
raise(SIGABRT);
}
/* If there is no user handler for SIGABRT or if the user
* handler returns, then exit from the program anyway
*/
if (__abort_behavior & _CALL_REPORTFAULT)
{
_call_reportfault(_CRT_DEBUGGER_ABORT, STATUS_FATAL_APP_EXIT, EXCEPTION_NONCONTINUABLE);
}
/* If we don't want to call ReportFault, then we call _exit(3), which is the
* same as invoking the default handler for SIGABRT
*/
_exit(3);
}从代码中可以看出,产生了一个SIGABRT终止信号通知。
有的模块在检测到异常时,还会调用DebugBreak API函数,会让调试器中断下来。关于DebugBreak函数的说明如下:
![图片[3]-C++软件异常分析概述-卡核](https://ziquyun.com/main/csdn/img?url=https%3A%2F%2Fimg-blog.csdnimg.cn%2F5a825adde3d7444ebf5a4df69e0e0b32.png%3Fx-oss-process%3Dimage%2Fwatermark%2Ctype_d3F5LXplbmhlaQ%2Cshadow_50%2Ctext_Q1NETiBAZHZsaW5rZXI%3D%2Csize_20%2Ccolor_FFFFFF%2Ct_70%2Cg_se%2Cx_16&rfUrl=https%3A%2F%2Fblog.csdn.net%2Fchenlycly%2Farticle%2Fdetails%2F123991269)
比如有一次在排查开源webrtc库中申请内存失败导致闪退问题时,webrtc库内部认为内存申请失败是致命错误,会调用abort函数强行终止进程。在调用abort函数之前,会先调用DebugBreak函数,如果当前windbg正挂在问题进程上,DebugBreak函数的调用会让windbg中断下来,这样就能让调试人员感知到问题了,就可以直接在windbg中直接查看此时的函数调用堆栈了,就能确定是什么操作触发的问题了。
4、开源的CrashRpt库存在的问题
很多厂商都在使用开源的CrashRpt异常捕获库,但原生的CrashRpt库是有缺陷的。很多大厂使用的应该是经过深度改进的CrashRpt库。
开源的CrashRpt异常捕获库是动态地将已加载的库的导入表中创建线程的API函数CreateThread HOOK成我们自定义的MyCreateThread函数(不管调用哪个创建线程的接口,最终都会走到CreateThread接口中的),这样就能在MyCreateThread中调用系统API函数SetUnhandledExceptionFilter给每个创建的线程挂载异常处理函数了。
但这种机制是有缺陷的,不能给软件的所有模块的线程挂载异常处理函数,只能给在CrashRpt库之前加载的库挂载异常处理函数,在CrashRpt之后加载的库就没法去HOOK了,这样就会导致没进行HOOK操作的那些库中发生的异常都捕获不到了。在exe启动时,会把所有依赖的库加载到进程空间中,我们没法控制所有的库都在CrashRpt库之前被加载的,这也导致了有些异常崩溃CrashRpt时捕获不到的。
后来我们对CrashRpt库进行了改进,使用微软开源的detours项目中的代码将windows系统库中的UnhandledExceptionFilter接口给HOOK掉。因为基本所有的异常都会最终进入到该函数中,我们将UnhandledExceptionFilter接口HOOK成我们自定义的接口,我们就能在该自定义的接口中感知到几乎所有的异常了。感知到异常后,就可以生成包含异常上下文的dump文件了。这样就能很好的解决老版本CrashRpt不能hook后加载的库的问题,新版本的CrashRpt就可以作用于当前进程的所有模块了,基本可以捕获到进程的所有异常了。
当然改进后的CrashRpt也不是100%的异常都能捕获到,但可以捕获大概90%以上的异常。对于捕获不到的场景,就需要将windbg挂载到目标进程上,让windbg去捕获了。







暂无评论内容