
目录
博文链接
初赛:
-
【2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题】3 问题二 思路和python实现
【2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题】4 问题三 思路和数据及参考资料 -
【2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题】5 完整方案和40页论文PDF下载
复赛:
下载链接
-
【2021 年 MathorCup 高校数学建模挑战赛—赛道A】二手车估价问题的数据分析及可视化 代码下载
-
[【2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题】问题一 Baseline 和数据 下载
-
【2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题】问题二 思路和python实现代码 下载
-
[【2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题】问题三 思路和数据及参考资料 下载
-
【2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题】5 完整方案和40页论文PDF下载
https://github.com/BetterBench/BetterBench-Shop
1 导入包
import datetime
import numpy as np
import pandas as pd
import numpy as np
from tqdm import tqdm
tqdm.pandas()
读取数据
file1.csv、file2.csv由“附件1:估价训练数据.txt”和“附件2:估价验证数据.txt”格式转换而来
train = pd.read_table('file1.csv',sep='\\t',)
test = pd.read_table('file2.csv',sep='\\t',)
2 特征工程
只使用缺失值较少或者没有的字段
column_tra = ["carid", "tradeTime", "brand", "serial", "model", "mileage", "color", "cityId", "carCode", "transferCount", "seatings", "registerDate",
"licenseDate", "country", "maketype", "modelyear", "displacement", "gearbox", "oiltype", "newprice", "anonymousFeature1", "anonymousFeature2",
"anonymousFeature3", "anonymousFeature5", "anonymousFeature6", "anonymousFeature11", "anonymousFeature12", "anonymousFeature14", "price"]
column_te = ["carid", "tradeTime", "brand", "serial", "model", "mileage", "color", "cityId", "carCode", "transferCount", "seatings", "registerDate",
"licenseDate", "country", "maketype", "modelyear", "displacement", "gearbox", "oiltype", "newprice", "anonymousFeature1", "anonymousFeature2",
"anonymousFeature3", "anonymousFeature5", "anonymousFeature6",
"anonymousFeature11", "anonymousFeature12", "anonymousFeature14"]
train = train[column_tra]
test = test[column_te]
2.1 缺失值处理
对于分类特征,填充众数
数据不完整
以下每个特征的众数我用字母替代,众数可以自己统计,或者下载完整代码
# 以下分类特征全部填充众数
train['carCode'] = train['carCode'].fillna(a)
train['modelyear'] = train['modelyear'].fillna(b)
train['country'] = train['country'].fillna(c)
train['maketype'] = train['maketype'].fillna(d)
train['gearbox'] = train['gearbox'].fillna(e)
train['anonymousFeature5'] = train['anonymousFeature5'].fillna(f)
test['carCode'] = test['carCode'].fillna(a)
test['modelyear'] = test['modelyear'].fillna(b)
test['country'] = test['country'].fillna(c)
test['maketype'] = test['maketype'].fillna(d)
test['gearbox'] = test['gearbox'].fillna(e)
test['anonymousFeature5'] = test['anonymousFeature5'].fillna(f)
train['anonymousFeature1'] = train['anonymousFeature1'].fillna(a)
# train['anonymousFeature4'] = train['anonymousFeature4'].fillna(b)
# train['anonymousFeature8'] = train['anonymousFeature8'].fillna(c)
# train['anonymousFeature9'] = train['anonymousFeature9'].fillna(d)
# train['anonymousFeature10'] = train['anonymousFeature10'].fillna(e)
train['anonymousFeature11'] = train['anonymousFeature11'].fillna(f)
test['anonymousFeature1'] = test['anonymousFeature1'].fillna(a)
# test['anonymousFeature4'] = test['anonymousFeature4'].fillna(b)
# test['anonymousFeature8'] = test['anonymousFeature8'].fillna(c)
# test['anonymousFeature9'] = test['anonymousFeature9'].fillna(d)
# test['anonymousFeature10'] = test['anonymousFeature10'].fillna(e)
test['anonymousFeature11'] = test['anonymousFeature11'].fillna(f)
2.2 提取时间特征
# # 时间处理(提取年月日)
train['tradeTime'] = pd.to_datetime(train['tradeTime'])
train['registerDate'] = pd.to_datetime(train['registerDate'])
train['licenseDate'] = pd.to_datetime(train['licenseDate'])
test['tradeTime'] = pd.to_datetime(test['tradeTime'])
test['registerDate'] = pd.to_datetime(test['registerDate'])
test['licenseDate'] = pd.to_datetime(test['licenseDate'])
train['tradeTime_year'] = train['tradeTime'].dt.year
train['tradeTime_month'] = train['tradeTime'].dt.month
train['tradeTime_day'] = train['tradeTime'].dt.day
train['registerDate_year'] = train['registerDate'].dt.year
train['registerDate_month'] = train['registerDate'].dt.month
train['registerDate_day'] = train['registerDate'].dt.day
test['tradeTime_year'] = test['tradeTime'].dt.year
test['tradeTime_month'] = test['tradeTime'].dt.month
test['tradeTime_day'] = test['tradeTime'].dt.day
test['registerDate_year'] = test['registerDate'].dt.year
test['registerDate_month'] = test['registerDate'].dt.month
test['registerDate_day'] = test['registerDate'].dt.day
2.3 匿名特征13的特征处理
代码不完整,差time_format函数,完整代码请下载
# # 匿名特征13(转化时间格式)
train = train[train['anonymousFeature13'].notna()]
train = train.reset_index()
test = test[test['anonymousFeature13'].notna()]
test = test.reset_index()
train['anonymousFeature13'].progress_apply(time_format)
test['anonymousFeature13'].progress_apply(time_format)
train['anonymousFeature13'] = pd.to_datetime(train['anonymousFeature13'])
test['anonymousFeature13'] = pd.to_datetime(test['anonymousFeature13'])
train['anonymousFeature13_year'] = train['anonymousFeature13'].dt.year
train['anonymousFeature13_month'] = train['anonymousFeature13'].dt.month
test['anonymousFeature13_year'] = test['anonymousFeature13'].dt.year
test['anonymousFeature13_month'] = test['anonymousFeature13'].dt.month
2.4 匿名特征12的处理
series1 = train['anonymousFeature12'].str.split('*', expand=True)
train['length'] = series1[0]
train['width'] = series1[1]
train['high'] = series1[2]
series2 = test['anonymousFeature12'].str.split('*', expand=True)
test['length'] = series2[0]
test['width'] = series2[1]
test['high'] = series2[2]
train['length'] = train['length'].astype(float)
train['width'] = train['width'].astype(float)
train['high'] = train['high'].astype(float)
test['length'] = test['length'].astype(float)
test['width'] = test['width'].astype(float)
test['high'] = test['high'].astype(float)
2.5 匿名特征11的处理
代码不完整,差dict字典,完整代码下载:
train['anonymousFeature11'] = train['anonymousFeature11'].map(dict)
test['anonymousFeature11'] = test['anonymousFeature11'].map(dict)
2.6 存储为csv
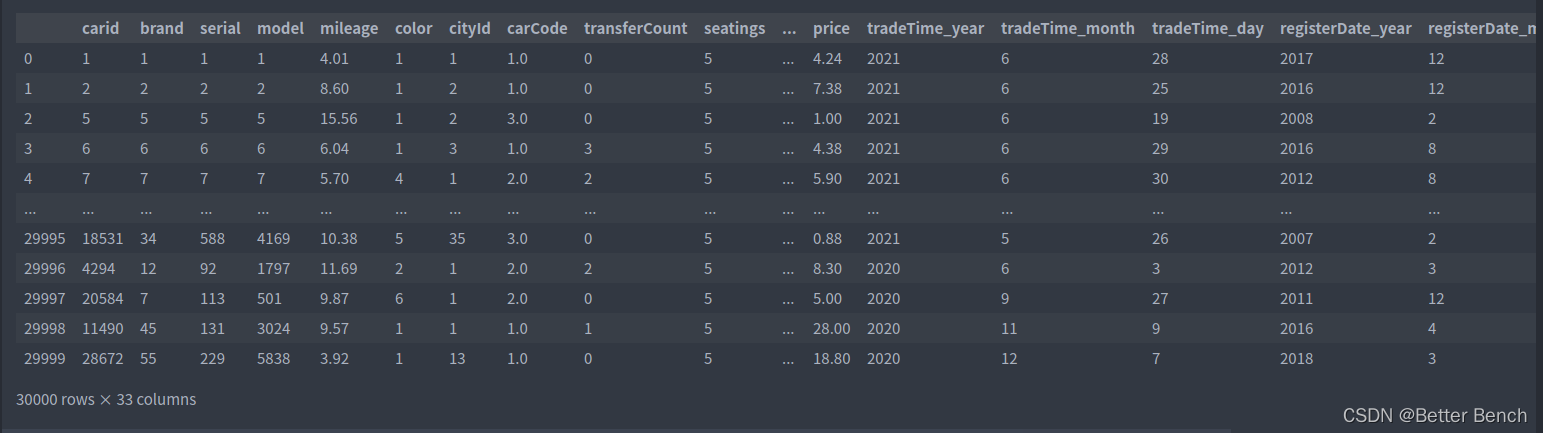
总共挖掘了33个特征,除了以上已有的特征提取外,还可以构造交叉特征,挖掘其他的特征。此处省略
train.to_csv('clear_train.csv',index=0)
test.to_csv('clear_test.csv',index=0)
3 特征筛选和降维
略。。。
4 模型训练
导入包
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
import lightgbm as lgb
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
import pandas as pd
import warnings
from sklearn.preprocessing import scale
from sklearn.model_selection import cross_val_score
import lightgbm as lgb
from sklearn.model_selection import KFold
import xgboost as xgb
from catboost import CatBoostRegressor
import time
import numpy as np
from sklearn.preprocessing import StandardScaler
读取数据
train = pd.read_csv('clear_train.csv')
test = pd.read_csv('clear_test.csv')
筛选数据并归一化,大于75的为异常值,直接舍弃
n_price = 75
train_X = train[train['price'] < n_price]
# 使用对数的右偏变换函数,将数据分布转为近似正态分布
train_X['price'] = np.log1p(train_X['price'])
train_y = train_X['price']
del train_X['price']
scaler = StandardScaler()
train_x = scaler.fit_transform(train_X)
test_x = scaler.fit_transform(test)
设计准确率评价函数

params = {'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'regression_l1',
'metric': 'mae',
'min_child_samples': 46,
'min_child_weight': 0.01,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 2,
'num_leaves': 32,
'max_depth': 8,
'n_jobs': -1,
'seed': 2019,
'verbose': -1,
}
def Accuracy(y_true, y_pred):
"""
参数:
y_true -- 测试集目标真实值
y_pred -- 测试集目标预测值
返回:
mape -- MAPE 评价指标
"""
#略。。
return Accuracy
5折划分训练,并预测测试集,生成提交文件
val_pred = np.zeros(len(train_x))
val_true = np.zeros(len(train_x))
preds = np.zeros(len(test_x))
folds = 5
# seeds = [1234]
# for seed in seeds:
kfold = KFold(n_splits=folds, shuffle=True, random_state=4321)
for fold, (trn_idx, val_idx) in enumerate(kfold.split(train_x, train_y)):
print('fold ', fold + 1)
x_trn, y_trn, x_val, y_val = train_x[trn_idx], train_y.iloc[trn_idx], train_x[val_idx], train_y.iloc[val_idx]
train_set = lgb.Dataset(x_trn, y_trn)
val_set = lgb.Dataset(x_val, y_val)
model = lgb.train(params, train_set, num_boost_round=5000,
valid_sets=(
train_set, val_set), early_stopping_rounds=500,
verbose_eval=False)
val_pred[val_idx] += model.predict(x_val, predict_disable_shape_check=True)
preds += model.predict(test_x, predict_disable_shape_check=True) / folds
val_true[val_idx] += y_val
Accuracy = Accuracy(val_true, val_pred)
print('-'*120)
print('Accuracy ', round(Accuracy, 5))
pd.DataFrame(preds).to_csv('估价模型结果.csv',header=0)
本地验证准确率为0.99+

生成的提交的数据如下











![[转]我国CAD软件产业亟待研究现状采取对策-卡核](https://www.caxkernel.com/wp-content/uploads/2024/07/frc-f080b20a9340c1a89c731029cb163f6a-212x300.png)







