
相关链接
1 题目
异常检测(异常诊断/发现)、异常预测、趋势预测,是智能运维中首当其冲需要解决的问题。这类问题是通过业务、系统、产品直接关联的 KPI 业务指标进行分析诊断,指标主要包括用户感知类(如页面打开延时)、服务性能(如用户点击量)、服务器硬件健康状况(如 CPU 利用率、内存使用率)等关键性能指标。
不同场景的运维,分析的指标种类差异较大,但都具备时序性特点,不同场景的 KPI 指标,以毫秒、秒、分钟、小时、天为时间间隔的数据序列都会出现, 有些复杂场景的业务,往往会混合多个时间间隔的数据,但均为随时间变化而变化的时序数据。
本次赛题以运营商基站 KPI 的性能指标为研究数据,数据是从 2021 年 8 月28 日 0 时至 9 月 25 日 23 时共 29 天 5 个基站覆盖的 58 个小区对应的 67 个 KPI 指标。其中,选取三个核心指标进行分析。
第一个指标:小区内的平均用户数,表示某基站覆盖的小区一定时间内通过手机在线的平均用户人数;
第二个指标:小区 PDCP 流量,通过小区 PDCP 层所发送的下行数据的总吞吐量(比特)与 小区PDCP 层所接收到的上行数据的总吞吐量(比特)两个指标求和得到,表示某基站覆盖的小区在一定时间内的上下行流量总和;
第三个指标:平均激活用户数,表示某基站覆盖的小区在一定时间内曾经注册过无线网络的平均人数。
针对上面三个指标,完成如下 3 个问题:
问题1异常检测:利用附件的指标数据,对所有小区在上述三个关键指标上

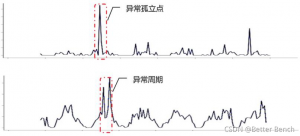
检测出这 29 天内共有多少个异常数值,其中异常数值包含以下两种情况:异常孤立点、异常周期。
汇总所有小区的异常情况填写如下表格。

问题2 异常预测:针对问题 1 检测出的异常数值,通过该异常数值前的数据建立预测模型,预测未来是否会发生异常数值。异常预测模型除了考虑模型准确率以外,还需要考虑两点:1)模型输入的时间跨度,输入数据的时间跨度越长, 即输入数据量越多,模型越复杂,会增加计算成本和模型鲁棒性,降低泛化能力; 2)模型输出时间跨度,即预测的时长,如果只能精准预测下一个时刻是否发生异常,在时效性上则只能提前一个小时,时效性上较弱。
问题 3 趋势预测:利用 2021 年 8 月 28 日 0 时至 9 月 25 日 23 时已有的数据,
预测未来三天(即 9 月 26 日 0 时-9 月 28 日 23 时)上述三个指标的取值。并完
整填写附件 2 中的预测值表格,单独上传到竞赛平台。
说明:
(1) 异常孤立点,在一段时间内仅有 1 个异常值;异常周期,在一段时间内有多个异常值。(时间范围、异常值范围需要参赛者自行设定并说明理由)。
(2) 在异常预测和趋势预测时,可借用其他指标作为辅助输入特征建模,如预测第 i 个指标第 t 时刻的数值或是否异常,可使用第 j 个指标 t 时刻前的数值作为输入,但不能以第 j 个指标第 t 时刻及之后的数值作为输入。
(3) 异常预测和趋势预测建模时,需考虑每个小区、基站之间的差异。可以针对每个小区、基站单独建模,也可以统一建模,最终以模型评价指标来评估。
(4) 第一题和第二题以 F1 值(2精确率召回率/(精确率+召回率))来评估模型优劣,第三题以 MAPE(平均绝对百分比误差)作为模型评估指标。
2 赛题解析
2.1 宏观的角度了解相关知识
第一问是一个异常检测问题、第二问是一个异常预测问题,可以看成是分类问题、第三问是一个时间序列KPI指标预测问题。
(1)对于异常检测,异常检测的可以考虑三种方式,第一种采用统计思维的方式,比如3-sigma和box-plot方式;第二种直接检测放,比如独立树IForest、RRCF、高斯混合GMM;第三种间接检测法,具有周期性的KPI,在检测前可通过先拟合波形,并与真是的指标值做对比,根据比较结果判断是否异常。拟合的方法比如机器学习、深度学习等等方式。
(2)对于时间序列的异常预测,可以做成分类问题,按时间序列预测的思路构造数据集,采用分类模型去做。重点有两个,一是选择小区去建模,还是选择整体数据去建模,二是怎么去构造数据集的标签。是选择一个指标的异常标签为准,还是取四个指标异常标签的并集或交集。
(3)对于时间序列的指标预测,重点有两点,一是在构造训练数据集,二是怎么去预测,是按照每个小区每个指标的预测,还是全部小区四个指标一块预测,即针对整体数据建模,还是针对小区和每个指标建模。完整的框架如下思维导图。

2.2 问题一
代码实现见【2021 高校大数据挑战赛-智能运维中的异常检测与趋势预测】2 方案设计与实现-Python
题目要求,需要对四个指标进行异常检测,并统计异常点个数和异常周期个数。将四个指标提取出来单独作为一个表来分析。
通过对数据分析,可以知道,数据是按时间点来排列的,每个时间点有58条数据,对应58个小区。如下图所示。有5个基站,每个小区对应一个基站,一个基站可以对应多个小区。

我的解决方案是使用ADTK异常检测工具包,对每个小区的时间序列进行异常检测,即分出来58个表来,分别对每个表的4个指标进行检测。取多种算法的并集。
第一种算法对第一个小区的四个指标的检测结果如下。

选择第一个指标为例,当多个算法的检测结果取并集后,检测的数量也变多。

2.3 问题二
代码实现见【2021 高校大数据挑战赛-智能运维中的异常检测与趋势预测】2 方案设计与实现-Python
对于预测未来的异常,我是将该问题看成是一个分类问题,针对所有数据进行建模。建立的模型是将小区ID、基站ID、四个指标作为模型输入,输出0或1。那首先需要去构造一个有标签的数据集。然后在训练之前,按照预测的目的,构造训练集,用一个样本对应下一个小样的标签构造成训练集,如下图所示。具体对应是对应下一个样本标签,还是对应下下个样本标签,这就是一个预测时长的概念问题。

(1)构造数据集
要构造一个有标签的数据集,思路是够每条的数据的四个指标都分别打一个标签,再取四个指标标签的或,作为每条样本数据的最终标签,每个先将整个是数据集按小区编号,分成58个表,每个表是按照时间顺序的,第一个小区的如下图所示,仔细看community_id是小区编号,base_id是基站编号,每条序列是按照时间序列排列的。

对每58个表中每一个表的四个进行异常检测,有有异常的就编码为1,无异常编码为0。直到把四个指标都标注完。再取四个指标标签的或。即只要一个指标异常,这一条数据就是异常点,并标签编码为1。反之,四个指标都不异常,该条数据就不异常,编码为0。最后把58个小区的数据再合并,按照最先的排序进行排列。

注意图中的标签0.0和1.0是浮点数而已,并不影响标注。
(2)构造训练集
初始一个预测长度和时间步长。这两个是超参数,是需要根据数据分析得出来的。不同的选择可能会导致模型不收敛。
预测长度指的是数据集所对应的标签是间隔了几个样本,比如下图的左边是间隔1个,预测长度就是1,右边是间隔2个,预测长度是2。时间步长,类似于窗口大小,选多少个样本为一个Batch。如下图中,有5个样本,那时间步长为5。

(3)模型选择
我选择的深度学习方式的LSTM拟合模型。
(4)模型评价
题目要求F1。F1 的计算公式如下
准确率(Precision):P=TP/(TP+FP)。通俗地讲,就是预测正确的正例数据占预测为正例数据的比例。
召回率(Recall):R=TP/(TP+FN)。通俗地讲,就是预测为正例的数据占实际为正例数据的比例
KaTeX parse error: Can't use function '$' in math mode at position 24: …rac{2×P×R}{P+R}$̲
2.3 问题三
代码实现见【2021 高校大数据挑战赛-智能运维中的异常检测与趋势预测】2 方案设计与实现-Python
问题三和问题二,我选择的模型是一样的,区别在于数据集的标签不一样,在此问题中,训练集中的标签是未来的数据。即建立的模型是将小区ID、基站ID、四个指标作为模型输入,输出四个指标。

选择部分数据拟合效果,如下图所示

3 不足与改进
(1)问题一
对于异常检测结果的好坏,我们没有找到一个合适的评价指标。我们选择了多种算法的并集的原因是因为在第二问中,如果取交集,得到的数据集模型没法收敛,没法拟合,是没有规律的,这一点不知道是否正确。
(2)问题二
我是选择对整体数据进行建模,就是一个多变量的预测问题,只想到了用LSTM去建模,并没有想到其他方法。比如ARIMA模型,我并不了解这个算法能否做多变量的预测。其实可以做单变量的预测,对每个小区进行建模,但是我为了与第三问保持模型的统一,就没有选择这种方法。就是单独建立58个模型,复杂度也不是特别高,这种方法有可能预测结果更可靠。
(3)问题三
这是一个时间序列预测问题,也是同样的对整个数据集进行建模,和第二问一样,也是一个多变量预测问题,没有想到有什么模型去解决。将这个问题视为多变量预测问题的原因是有两个,一是每条数据中,考虑到了有小区编号、基站编号,可以将这两者变量作为特征,不需要单独去考虑对小区进行建模。二是也考虑过选择对每个小区去建模,那还需要对四个指标分别建模,总共就需要训练4*58个模型,这模型的复杂度就很高。对未来三天数据的预测,操作起来很久麻烦。需要对每个小区的序列进行预测,再合并成提交的文件。
(4)整个异常检测的方法论,我还并没有完全掌握,都是现学现卖,在问题的分析中,少了很多分析过程和相应方法的使用。比如对序列周期的检测,这块虽然做了,但是是队友做的,我并不能保证这块是否有必要,以及方法是否正确。










![[转]我国CAD软件产业亟待研究现状采取对策-卡核](https://www.caxkernel.com/wp-content/uploads/2024/07/frc-f080b20a9340c1a89c731029cb163f6a-212x300.png)






